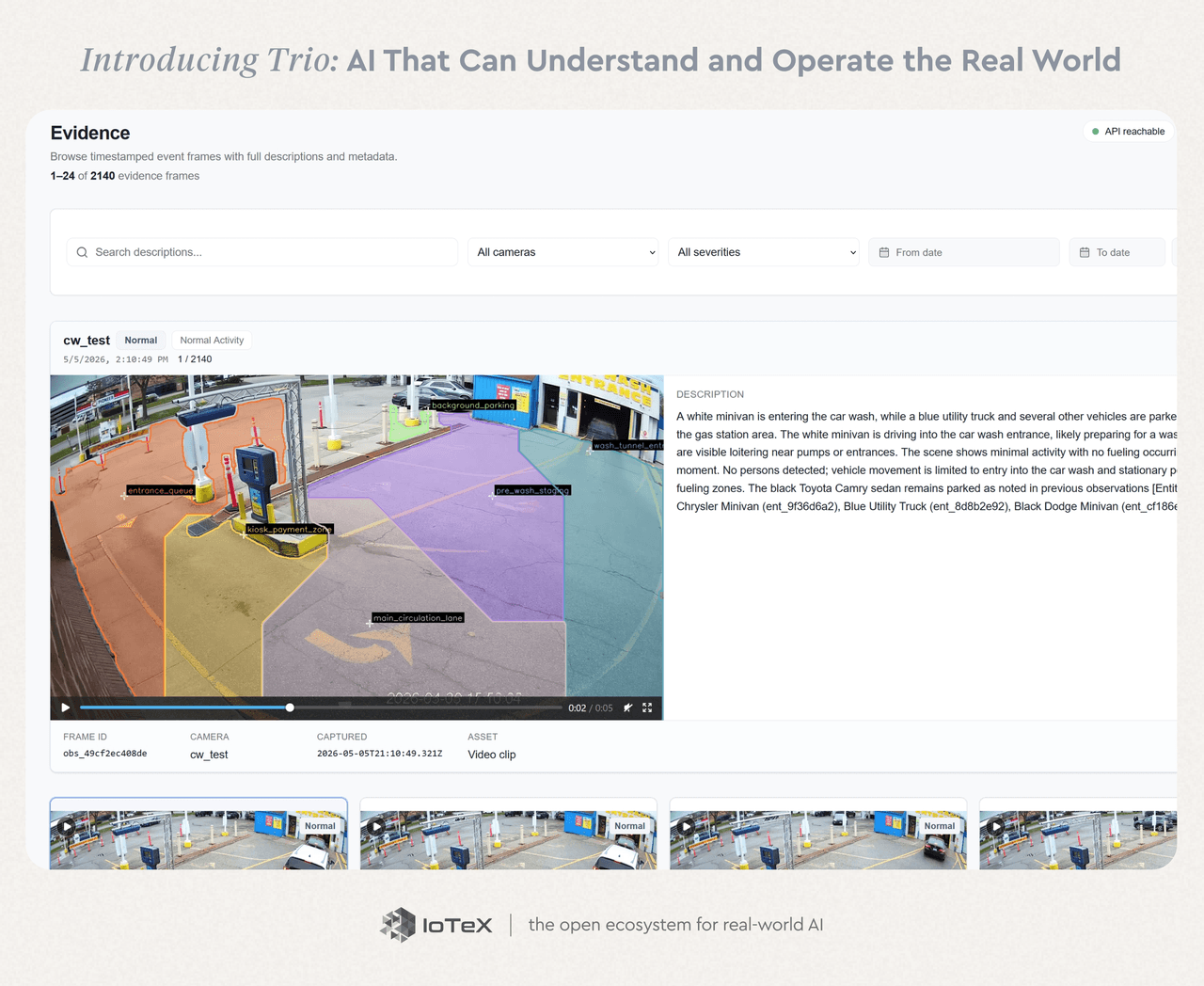
Introducing Trio: AI That Can Understand and Operate the Real World

Over the past year, AI has unleashed incredible capabilities that are revolutionizing the way we live and work. From AI agents that can refactor entire codebases overnight to LLMs that can execute hours-long research tasks, AI is fundamentally transforming how we approach digital work. But the next chapter of AI will not be written in the digital Cloud – it will be written in the physical world. From stores to warehouses to care centers to factories and other physical environments, a new wave of AI models and infrastructure that can perceive raw reality and orchestrate intelligent actions in the real world is coming.
In our previous blogs on The Awakening of the Physical World and our Anti-Roadmap for 2026, we outlined the forces driving this shift from AI that lives in your screen to AI that lives in the physical world. Small, task-specific AI models will concentrate domain expertise to perform specialized tasks. Compute will be pushed from massive centralized data centers to the distributed edge. Machines will be equipped with new visual, audio, and sensor insights so they can see, hear, and sense just like humans. Embodied intelligence will finally step off the screen and into physical environments. We made the case, and we have been diligently building new AI infrastructure like QuickSilver and ioSwarm that are already equipping AI builders with impactful tools. And now, the IoTeX team is excited to share our latest initiatives that focus on building the AI model that will truly bring our vision of Real-World AI to life.
That model is Trio, a foundation model for Real-World AI that can understand and operate the physical world. Trio gets its name from our vision to give AI the ability to see, hear, and sense by fusing video, audio, and sensor data from real-world devices. A super-intelligent brain trained not on the internet, but on the operational reality of the places where the physical economy actually runs. Trio turns the raw video, audio, and sensor signals a physical space already emits into a structured understanding of what is happening, why it is happening, and what should happen next.
This post is not a launch announcement, but rather a status update from a team going all-in on a thesis that has crystallized over a year of building: Trio will be one of the foundation models that let AI not just understand the physical world, but trigger intelligent actions to operate the physical world. Early research benchmarks have come back strongly and our first cohort of design partners are now helping us bring Trio into real-world environments. The work is in motion, and we want to take this time to share where we are headed in the coming months.
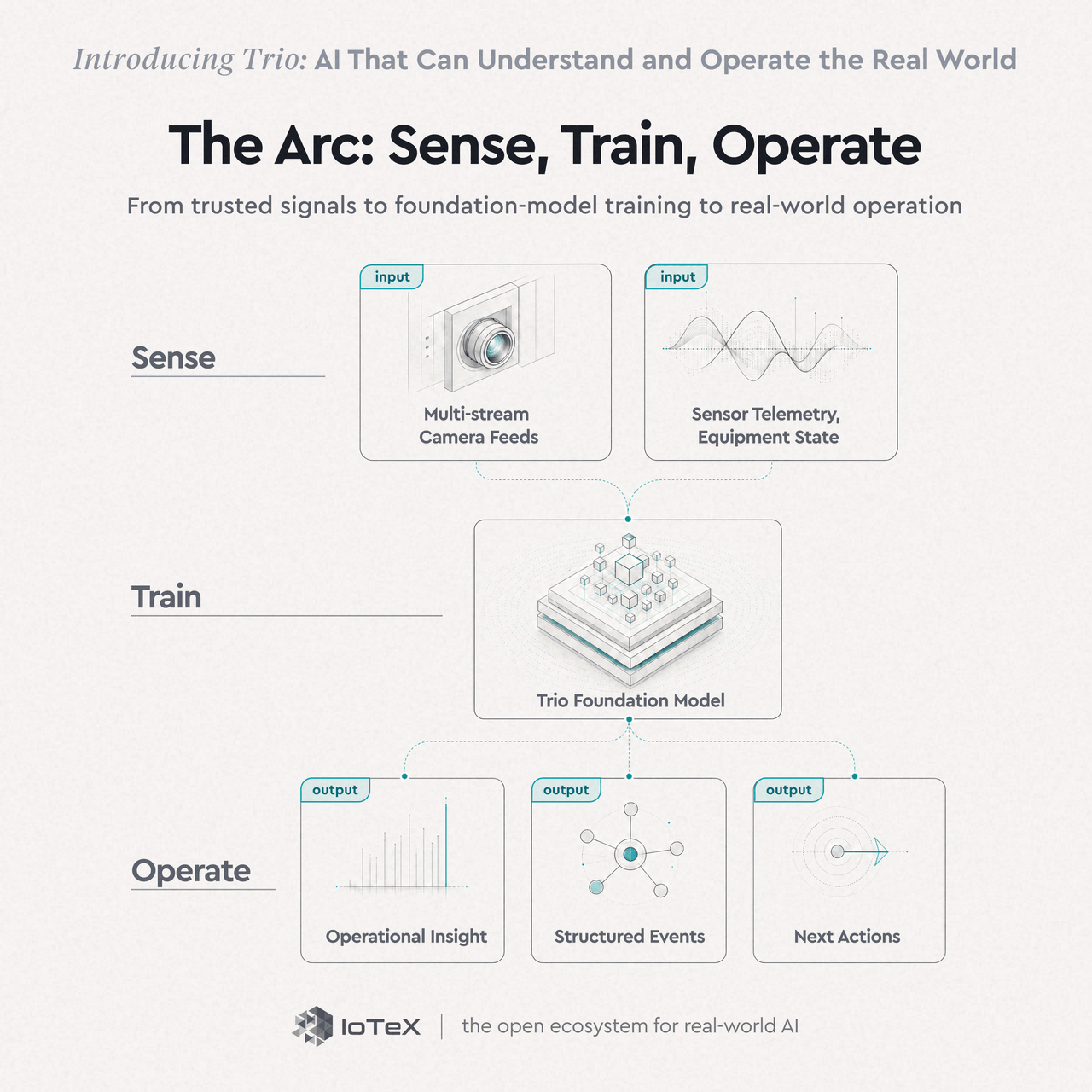
The Arc: Sense, Train, Operate
Our thesis for Trio unfolds in an arc across three movements, each one building on the last.
Sense: The first movement is about documenting the physical world in a verifiable data layer, converting physical phenomena into AI-ready data. This sounds obvious until you realize that the physical world does not self-document the way software does. A forklift will not generate a log entry when its driver hits a warehouse rack. A pipe will not file a ticket before it bursts. A parking lot will not track and record intruders overnight. For nearly a decade, IoTeX has been building the infrastructure that makes it possible to instrument physical spaces at-scale and verify that the data coming back is trustworthy. That foundation is now in place.
Train: The second movement is where Trio trains new AI models on the signals that cameras and sensors produce, not on internet text or scraped imagery. Today's models know what a warehouse looks like because they have seen stock photos of warehouses. But they do not actually know the intricacies of operating a warehouse — the rhythm of a loading dock across a twelve-hour shift, the specific sound a compressor makes three days before it seizes, the way foot traffic patterns shift across a retail floor when it rains. Trio ingests millions of hours of streaming data from real-world businesses and uses it to build pattern recognition for physical world automation.
Operate: The third movement closes the loop by feeding the model back into the physical world it was trained on. In the near-term, this means delivering insights to human operators in the form of alerts and digests, which provide users with an intimate understanding of physical environments. Over the longer arc, it means issuing commands directly to autonomous equipment and agents. For example, telling a floor scrubber to reroute around a spill it detected on camera, scheduling maintenance before a failing bearing stops a production line, or flagging the anomaly across multiple cameras that no human supervisor was ever going to catch on their own.
We spent most of the last decade on the first movement. With Trio we are squarely in the second and third movements, not as a research exercise but as a product being built with real design partners in real environments.
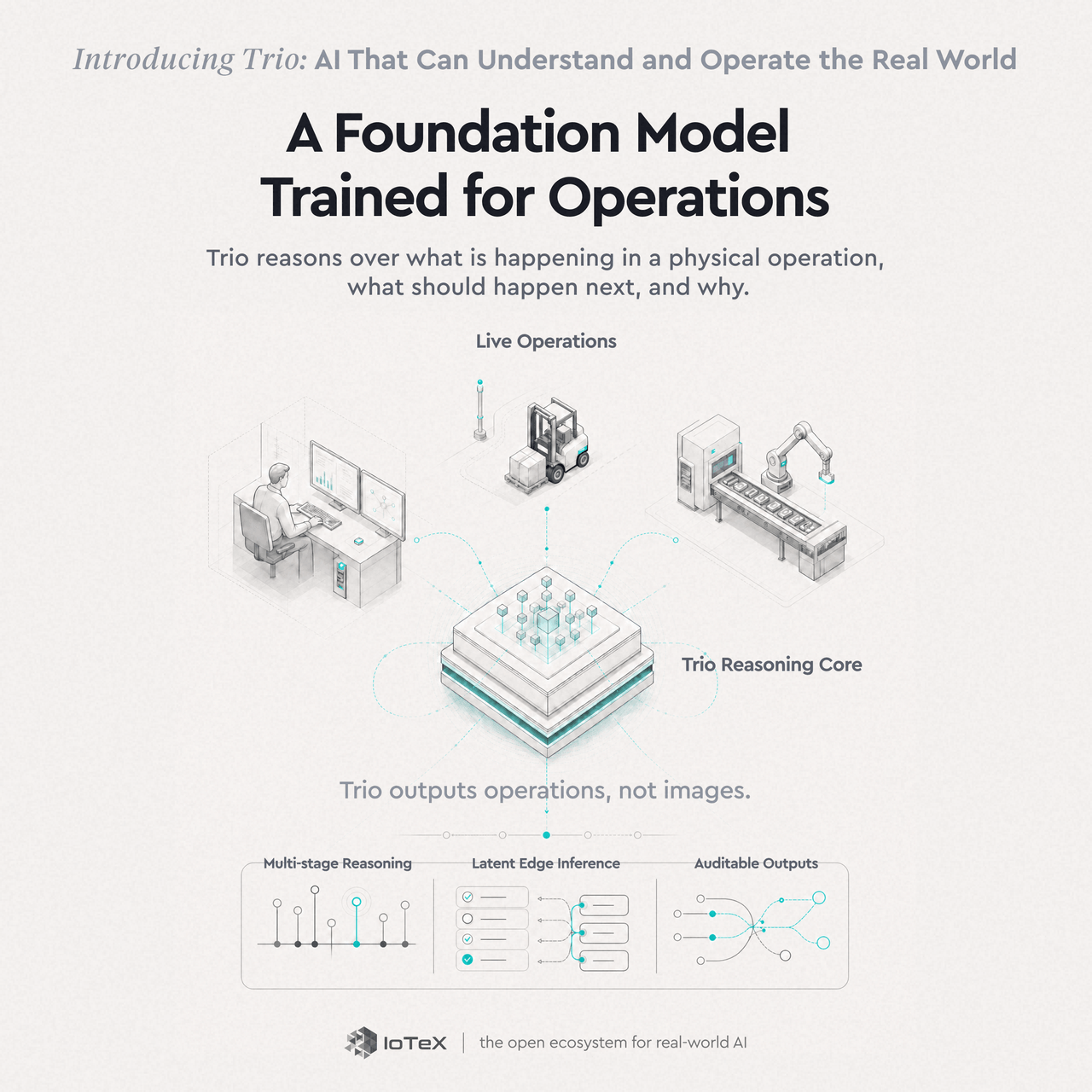
A Foundation Model for Real-World Operations
Trio is not a detection model that spots objects in a frame or a vision language model that captions scenes after the fact. It is a foundation model that reasons about physical operations the way an experienced manager reads a floor, understanding what is happening now and predicting what should happen next.
Most AI solutions shipped today are point solutions built for one scenario by one team, which break the moment an operator asks a question it was not programmed to answer. Trio takes an entirely different approach by offering a single model that generalizes across environments and learns the shared physics that underlie every operational space. Whether the setting is a loading dock, a wash bay, or a care home hallway, all these environments share a fundamental structure with entities moving through a defined space with intent. Vertical SaaS treats those spaces as separate problems, while Trio treats them as the same problem with unique traits.
This puts Trio in a different lane from both of the main research directions competing to bring AI into the physical world. The generative world model lines (V-JEPA, World Labs, Genie, Cosmos) render and imagine new environments, generating synthetic scenes and simulating what could happen. Trio is built for real-time decisioning on live signals from spaces that already exist. The robotic vision language action lines (Physical Intelligence, Figure, Skill) are single agent and egocentric, driving one robot through one task. Trio scales that thinking to an entire operation, reasoning about what a shift should do next rather than what an arm should reach for.
This bet is feasible because of data, and the data is the result of eight years of infrastructure. More than ten million connected devices continuously emit verified, timestamped signals from machines and sensors in the field, and that substrate grows every minute the network is online. Internet video teaches a model how the world looks; our substrate teaches a model how the world runs.
Three architectural properties make Trio work where general purpose AI cannot. First, multi-entity reasoning across long horizons: on the Warehouse v2 benchmark, our latent world model outperforms the next best baseline by fifteen percent on action recognition accuracy — work under review at NeurIPS 2026. Second, latent reasoning on edge silicon means a device with the profile of an Apple Silicon chip or Jetson Orin can run real-time inference with no cloud round trip and no handoff to a remote model, an approach formalized in our Depth-of-Thought paper. Third, an auditable inference trail: every event carries a structured trace of what Trio saw and how it reasoned, which an operator, auditor, or autonomous agent can inspect, contest, and act on. The cryptographic version of that trace, using zero knowledge proofs over neural networks, points toward a future where operational decisions become formally verifiable.
What's Happening Now and Next
Trio learns from the signals the physical world is already emitting, from multi-stream camera feeds and sensor telemetry to motion patterns, equipment state, and the texture of a space while real world operations are happening. A car wash bay, a kennel run, and a warehouse aisle each broadcast a structured story about their own operations, and today most of that story is simply discarded because no system exists to listen.
Trio is already running with an early cohort of design partners as an operations copilot, surfacing structured events like throughput drops, quality variance, fraud signals, and safety incidents through dashboards, alerts, and natural language chat where operators ask questions in plain English and get answers drawn from the live state of the space they run. This is only the first deployment surface, because the same foundation model that writes alerts for a human today will eventually issue commands to autonomous agents and robotic systems, and the brain stays the same even as the set of effectors grows.
Three forces are converging to make this moment different. Edge silicon can now handle real-time operational reasoning without depending on a cloud round trip, multi-entity scene understanding has crossed a research threshold that single object detection never approached, and the millions of businesses that operate the physical economy are ready for what may be the most underpriced capability in AI today — a brain on top of the sensors they already own, delivering autonomy without requiring new robots.
Trio is actively evolving, but the early results are strong, the first customers are seeing real business impact, and the IoTeX team is fully committed to unleashing Trio to the masses. We will share more in the coming weeks about what Trio sees, how it sees it, who is running on it, and what it lets the physical world do next.